
Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more.——pandas-dev
摘要Pandas 套件是 Python 用來處理表格型態資料的核心套件,利用 DataFrame 類別實踐了資料分析師熟悉的試算表(Excel Spreadsheet)與資料集(Datasets)操作處理;在這個小節中包含了簡介、描述她所因應的痛點以及如何創建Pandas重要的類別:Series 、DataFrame 與 Index 。

關於 Pandas
Python 語言一直都以擅長資料處理著名,在網頁資料擷取與資料庫串接上被資料工程師廣泛使用,但由於欠缺 Excel、R、SAS、SPSS 或 Stata 等普遍具有「列索引」以及「欄標籤」的資料集類別,在資料流程中必須將分析的階段外包給更專精於統計分析的軟體(像是 Excel 與 SPSS)或程式語言(R、SAS 與 Stata)。
Pandas 扮演著 Python 資料科學應用的最後一塊拼圖,她是構建於 NumPy 之上的套件,將 R 語言中廣受歡迎的資料框結構納入,除了儲存異質資料的基礎功能和敘述統計的方法,也提供多數資料庫系統與試算表使用者都熟悉的功能,像是變數選擇、觀測值篩選、資料排序、變數衍生加工、遺漏值處理、分組摘要以及樞紐分析等;Pandas 對表格式資料的支援不但很全面,甚至連基礎輸入輸出和視覺化功能都有涵蓋。
除了廣為人知的 DataFrame 類別,Pandas 亦創建了 Series 與 Panel 兩種類別,其中 Series 是附加標籤的一維陣列,而 Panel 是附加通常表現為時間軸的資料框;事實上 Panel 、DataFrame 與 Series 正是 Pandas 套件命名的緣由,而非與熊貓有著什麼瓜葛。
起步走
執行 Python 的載入指令確認環境中是否安裝了 Pandas 可供使用。如果安裝妥當,應該可以得到版本資訊的回應:
## 0.24.2
假若得到的回應是:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'pandas'
表示目前所處的 Python 環境沒有安裝 NumPy,在命令列中輸入 pip install --user pandas 即可完成安裝。
在 Jupyter Notebook 或 Google Colab 中以 pd.<TAB> 與 pd? 可以獲得函數名稱提示以及說明文件幫助。
獲得函數名稱提示以及說明文件幫助
痛點
模組、套件或函式庫的開發多半起源於某些痛點,就像創新產品的問世一般,那麼具體來說,Python 目前的基礎資料結構 list、tuple、dict 與 set 或者先前介紹過的 N 維陣列 ndarray 會讓資料分析師覺得有不足的地方呢?
擺放在不同物件中的資料無法很單純地「連動」處理就是其中一個通點,試想著以下這個應用情境:我們希望先將 Yahoo! 奇摩股市 - 上市成交價排行頁面中的股票代號/名稱與成交價擷取出來。
import requests
from bs4 import BeautifulSoup
def get_stock_data(): r = requests.get("https://tw.stock.yahoo.com/d/i/rank.php?t=pri&e=tse&n=100") soup = BeautifulSoup(r.text) stocks = [i.text for i in soup.select(".name a")] prices = [float(i.text) for i in soup.select(".name+ td")] return stocks, prices
stocks, prices = get_stock_data()
print(stocks)
print(prices)## ['3008 大立光', '6415 矽力-KY', '6409 旭隼', '5269 祥碩', '6669 緯穎', '2207 和泰車', '3406 玉晶光', '1476 儒鴻', '2454 聯發科', '3563 牧德', '2059 川湖', '1590 亞德客-KY', '2912 統一超', '2231 為升', '8464 億豐', '2395 研華', '8341 日友', '8454 富邦媒', '2049 上銀', '2330 台積電', '3533 嘉澤', '6230 超眾', '2227 裕日車', '3443 創意', '2327 國巨', '8462 柏文', '6414 樺漢', '6452 康友-KY', '4137 麗豐-KY', '3665 貿聯-KY', '2474 可成', '2379 瑞昱', '9921 巨大', '2357 華碩', '9910 豐泰', '1256 鮮活果汁-KY', '1707 葡萄王', '3034 聯詠', '1477 聚陽', '6666 羅麗芬-KY', '9914 美利達', '4943 康控-KY', '3130 一零四', '6670 復盛應用', '2707 晶華', '4766 南寶', '2345 智邦', '2492 華新科', '4438 廣越', '8070 長華', '4536 拓凱', '8016 矽創', '4968 立積', '2360 致茂', '2404 漢唐', '8422 可寧衛', '4551 智伸科', '2723 美食-KY', '1537 廣隆', '4763 材料-KY', '2439 美律', '2308 台達電', '6504 南六', '3653 健策', '6213 聯茂', '3023 信邦', '2383 台光電', '1558 伸興', '3376 新日興', '8499 鼎炫-KY', '3661 世芯-KY', '5288 豐祥-KY', '8482 商億-KY', '2228 劍麟', '8480 泰昇-KY', '5871 中租-KY', '6533 晶心科', '1723 中碳', '1232 大統益', '6271 同欣電', '4912 聯德控股-KY', '4958 臻鼎-KY', '8081 致新', '6451 訊芯-KY', '1536 和大', '3413 京鼎', '6176 瑞儀', '9941 裕融', '3044 健鼎', '3045 台灣大', '8114 振樺電', '2412 中華電', '6464 台數科', '3596 智易', '6456 GIS-KY', '008201 BP上證50', '3454 晶睿', '2939 凱羿-KY', '4190 佐登-KY', '3532 台勝科']
## [3885.0, 705.0, 644.0, 509.0, 450.0, 435.5, 425.0, 386.0, 370.5, 339.0, 330.0, 327.5, 292.5, 286.5, 268.5, 267.5, 262.5, 259.5, 259.0, 257.5, 249.0, 248.0, 247.5, 238.0, 236.0, 231.0, 225.5, 224.0, 223.0, 222.5, 221.0, 218.0, 214.5, 205.0, 204.0, 203.0, 194.5, 193.0, 185.0, 184.0, 180.0, 171.5, 170.0, 168.0, 166.0, 165.5, 164.0, 160.0, 159.0, 158.5, 158.5, 158.0, 158.0, 158.0, 156.5, 153.0, 152.0, 150.5, 149.5, 148.0, 147.5, 146.0, 146.0, 144.0, 142.5, 138.0, 133.5, 133.0, 132.0, 131.5, 131.5, 129.5, 129.0, 128.5, 127.5, 127.0, 126.5, 126.0, 121.0, 120.0, 119.5, 118.5, 118.0, 117.5, 116.5, 116.5, 115.0, 114.0, 113.5, 112.5, 110.5, 110.0, 107.5, 106.0, 105.5, 104.65, 104.0, 103.5, 103.5, 103.0]
接著將股票代號/名稱帶有 KY 字樣的成交價中位數計算出來,在這個需求中要根據 stocks 中的每個文字樣式對 prices 中的數值篩選。
from statistics import median ky_prices = [j for i, j in zip(stocks, prices) if "KY" in i] print(median(ky_prices))
## 131.5
具體來說連結 stocks 與 prices 兩個 list 物件的是各自的索引順序,並不能連動操作篩選與中位數運算。而 DataFrame 因為將 stocks 與 prices 利用共同的所以連結,可以連動操作篩選與中位數運算。
import pandas as pd
df = pd.DataFrame()
df["stock"] = stocks
df["price"] = prices
print(df[df["stock"].str.contains("KY")]["price"].median())## 131.5
在進一步討論如何應用 Pandas 在資料分析的任務之前,我們要先認識四個由 Pandas 提供的基礎資料結構:
Series
DataFrame
Panel(自 Pandas 0.20.0 版本之後取消了此類別)
Index
Pandas 中的 Series
我們可以使用 pd.Series() 函數創建 Series 類別,Series 從 ndarray 繼承了所有特性,並加上一組 Index。
import pandas as pd movie_ratings = [8.0, 7.3, 8.5, 8.6] ser = pd.Series(movie_ratings) print(type(ser)) print(ser) print(ser[3])
## <class 'pandas.core.series.Series'>
## 0 8.0
## 1 7.3
## 2 8.5
## 3 8.6
## dtype: float64
## 8.6
這使得她不只能夠透過絕對位置來索引,亦可以透過像操作 dict 一般,以鍵(Key)作為選擇索引依據。
import pandas as pd movie_ratings = [8.0, 7.3, 8.5, 8.6] movie_titles = ["The Avengers", "Avengers: Age of Ultron", "Avengers: Infinity War", "Avengers: Endgame"] ser = pd.Series(movie_ratings, index=movie_titles) print(ser) print(ser["Avengers: Endgame"])
## The Avengers 8.0
## Avengers: Age of Ultron 7.3
## Avengers: Infinity War 8.5
## Avengers: Endgame 8.6
## dtype: float64
## 8.6
我們可以將 Series 視為一種較為泛用的 ndarray,同時具備 list 和 dict 的特性,以 .index 屬性與 .values 屬性可以將 Series 拆分為 Index 類別與 ndarray。
import pandas as pd movie_ratings = [8.0, 7.3, 8.5, 8.6] movie_titles = ["The Avengers", "Avengers: Age of Ultron", "Avengers: Infinity War", "Avengers: Endgame"] ser = pd.Series(movie_ratings, index=movie_titles) print(ser.index) print(ser.values) print(type(ser.index)) print(type(ser.values))
## Index(['The Avengers', 'Avengers: Age of Ultron', 'Avengers: Infinity War',
## 'Avengers: Endgame'],
## dtype='object')
## [8. 7.3 8.5 8.6]
## <class 'pandas.core.indexes.base.Index'>
## <class 'numpy.ndarray'>
Pandas 中的 DataFrame
我們可以使用 pd.DataFrame() 函數創建 DataFrame 類別。
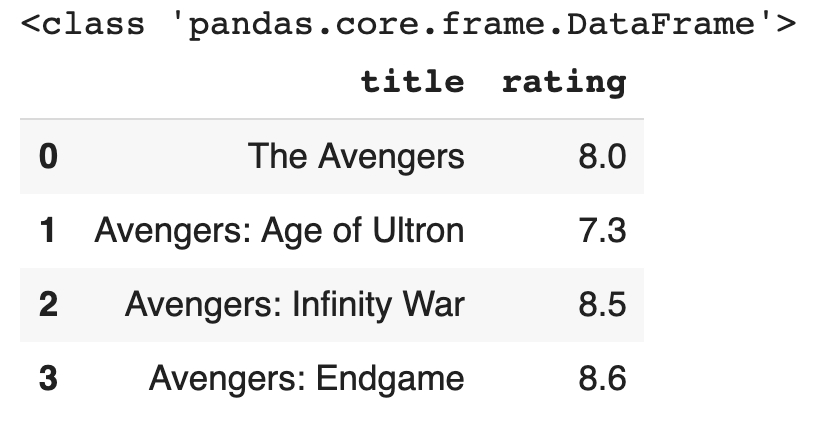
使用 pd.DataFrame() 函數創建 DataFrame 類別
DataFrame 將多組共享 Index 的 Series 組合為一個具備列索引(row index)與欄標籤(column label)的資料集,我們可以進一步分拆成列索引、欄標籤與 Series。
## RangeIndex(start=0, stop=4, step=1)
## Index(['title', 'rating'], dtype='object')
## 0 The Avengers
## 1 Avengers: Age of Ultron
## 2 Avengers: Infinity War
## 3 Avengers: Endgame
## Name: title, dtype: object
## 0 8.0
## 1 7.3
## 2 8.5
## 3 8.6
## Name: rating, dtype: float64
Pandas 中的 Panel
自 Pandas 0.20.0 版本之後取消了 Panel 類別。
Pandas 中的 Index
不論是 Series 或 DataFrame 物件都包含一個 Index 類別,作為萃取以及更新資料的根據,Index 可以被視為是一種結合了 tuple 的不可變(Immutable)特性以及 set 集合運算特性的資料結構類別,我們可以使用 pd.Index() 函數創建出下列的範例。
import pandas as pd pd_index = pd.Index([0, 2, 3, 4]) print(type(pd_index)) print(pd_index) pd_index[0] = 1
## <class 'pandas.core.indexes.numeric.Int64Index'>
## Int64Index([0, 2, 3, 4], dtype='int64')
## ---------------------------------------------------------------------------
## TypeError Traceback (most recent call last)
## <ipython-input-11-15d56bc6719d> in <module>()
## 3 pd_index = pd.Index([0, 2, 3, 4])
## 4 print(pd_index)
## ----> 5 pd_index[0] = 1
##
## /usr/local/lib/python3.6/dist-packages/pandas/core/indexes/base.py in __setitem__(self, key, value)
## 3936
## 3937 def __setitem__(self, key, value):
## -> 3938 raise TypeError("Index does not support mutable operations")
## 3939
## 3940 def __getitem__(self, key):
##
## TypeError: Index does not support mutable operations
除了創建後不能更新,Index 也支援 Set 類別的集合運算,可以對兩組 Index 類別(如例子中的五個奇數、四個質數)使用交集、聯集與 XOR(Exclusive OR)。
import pandas as pd odds_index = pd.Index([1, 3, 5, 7, 9]) primes_index = pd.Index([2, 3, 5, 7]) print(odds_index & primes_index) # and print(odds_index | primes_index) # or print(odds_index ^ primes_index) # exclusive or
## Int64Index([3, 5, 7], dtype='int64')
## Int64Index([1, 2, 3, 5, 7, 9], dtype='int64')
## Int64Index([1, 2, 9], dtype='int64')
截至目前為止,我們已經掌握使用 Pandas 函數創建 Series、DataFrame 與 Index 的方式,並準備好在後續的小節研究如何對 Pandas 的主要資料結構做基本處理、操作及運算。
YOTTA 你最專業的學習夥伴,提供優質內容與有趣觀點,擴大豐富你的視野。
- 訂閱Pyradise的專欄,定期收到新文章通知。
- 延伸學習:Python與前端技術綜合技能養成|20小時從零建構即時資訊儀表板

延伸閱讀:
封面圖片來源:unsplash
